Stop Building Custom Scrapers for RAG
Feed your RAG stack one clean Markdown file per source. SiteToMarkdown handles the crawling, cleaning, and formatting so you can focus on your retrieval pipeline.
https://docs.stripe.com
Ready
loader = UnstructuredMarkdownLoader("./stripe.md")
docs = loader.load()
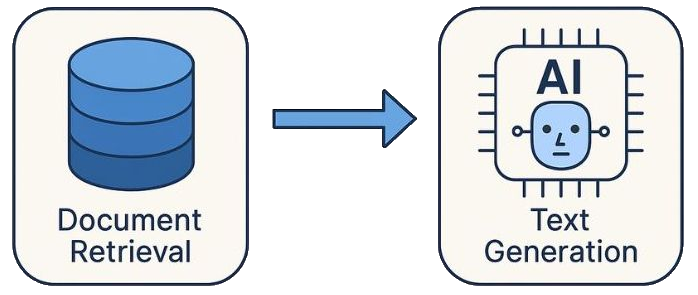
RAG combines retrieval from a knowledge base with generation by an LLM.
What is Retrieval-Augmented Generation (RAG)?
RAG is a technique that enhances Large Language Models (LLMs) by retrieving relevant data from your external knowledge base before generating an answer. This allows AI to answer questions about your specific documentation, private data, or real-time information that wasn't in its training set.
The "Custom Scraper" Trap
Building a RAG pipeline is hard enough without having to maintain a custom scraper for every data source.
- Brittle Selectors: One HTML change breaks your entire ingestion pipeline.
-
JS Rendering: Simple
requestsorcurlwon't work on modern docs sites. - Noise: Navbars, footers, and ads pollute your vector store embeddings.
The SiteToMarkdown Solution
We treat documentation sites as a single unit of knowledge.
- One URL → One File: Give us the root URL, get back a comprehensive Markdown file.
- LLM-Optimized: Clean Markdown structure preserves hierarchy for better chunking.
- Universal Format: Works with LangChain, LlamaIndex, Haystack, and more.
Integration Guide
How to load SiteToMarkdown datasets into your favorite RAG frameworks.
LangChain
Use the UnstructuredMarkdownLoader from the community package to load the file into Document objects.
from langchain_community.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("./stripe_docs.md")
docs = loader.load()
# Ready for splitting and embedding
print(f"Loaded {len(docs)} documents")
Haystack
Use the MarkdownToDocument converter component in your pipeline.
from haystack.components.converters import MarkdownToDocument converter = MarkdownToDocument() results = converter.run(sources=["./stripe_docs.md"]) documents = results["documents"] # Ready for indexing
RAGatouille
Read the file content and pass it directly to the trainer or indexer.
from ragatouille import RAGTrainer
with open("./stripe_docs.md", "r") as f:
markdown_content = f.read()
trainer = RAGTrainer(model_name="MyColBERT", pretrained_model_name="colbert-ir/colbertv2.0")
trainer.prepare_training_data(raw_data=[markdown_content], data_out_path="./data/")
RagFlow
Upload the Markdown file directly to your Knowledge Base. RagFlow's Deep Document Understanding engine handles the parsing and chunking automatically.
Why Markdown is Best for RAG
Raw HTML is full of noise. PDF is hard to parse. Markdown is the sweet spot for LLMs.
Structure Preservation
Headings (#, ##) naturally define semantic chunks, making it easier for splitters to keep related context together.
Token Efficiency
No <div> soup. Markdown is dense and information-rich, saving you money on embedding and storage costs.
Code Friendly
Code blocks are preserved with language tags, which is critical for technical documentation RAG.
Generate ingestion-ready sources automatically with the API
Use the SiteToMarkdown API as a pre-ingestion stage in your RAG pipeline so each run starts from fresh, clean Markdown.
- Submit source URLs before chunk/embed jobs begin.
- Wait for completion and download the latest markdown artifacts.
- Pass those files into your loader/splitter stack for deterministic ingestion.